
Sometimes you hear engineering terms, without fully understanding what they mean in reality. Brian Muyambo, Front End Engineer at Goodlord, had this experience with microservices so he researched more about the topic - and this is what he learned.

Have you found yourself nodding along to a conversation about microservices - without fully understanding them? I used to find myself in meetings with more senior members of the team discussing the subject and honestly having no idea what was actually going on. If you find yourself in the same situation, what I've learned to better follow, understand and participate in conversations around microservices might help you stop plotting your escape into friendlier topics.
What exactly are microservices?
Let's start by explaining exactly what we mean by microservices and what they aim to achieve. Microservices are a way of breaking up a monolith into smaller, more manageable pieces called services. There are two simple rules that this architectural style must follow:
- Each service created would need to contain everything needed to make a single feature of our application work independently, including having its own database
- No service should ever directly reach into another services database directly. Instead, everything is done through API calls
By following both of these points, a microservice architecture can achieve high uptime and reliability as each service will be self contained. It eliminates any dependencies between services and has already started moving away from the fragility of a monolith. Each service would be expected to function normally, regardless of the state of any other service in our app.
This kind of approach is not without its downsides. Managing data becomes very tricky, especially when we have two or more services that need access to the same data, as the solution isn’t as simple as just duplicating the data between two databases. We now need to consider what happens when that shared data changes in one or both databases - how do we know which one is correct? Modelling and syncing data between services is a real challenge, and that's where some of the complexity of adopting microservices comes into play.
When are they needed?
So, now you might be wondering why you would even need to go through the hassle, and the answer is...you probably don’t, at least not until your monolith has become too big and complicated to manage. You’ll know you’ve reached this point when a good folder structure and other methods of code reuse that served you well before no longer seem as effective, and there’s now lack of confidence in changes as, if a single part of it is down, most likely everything will be. You’re afraid to make changes due to potential side effects and on top of this you would also have a significantly harder time adopting new technologies as the scope of things affected would be much larger. That may be the point to consider microservices.
What are the benefits of microservices?
Microservices can mean:
- Higher uptime, reliability, and a less fragile system
- Reduced complexity due to the limited scope of the service - although the way the services communicate can add some of that complexity back into the system
- Technology stacks that are easier to build, maintain, deploy and debug
Services would also be a lot easier to understand and work with, as we know we’re only working on a service focused around a specific feature.
So that's what microservices are and how they can help. But how can we make them work efficiently?
Microservices in practice
Synchronous communication between services
A synchronous style of communication between services means that all services are communicating by making direct requests to each other to get or send some data. This approach is fairly easy to understand. However, we'd have to not be overly concerned with performance - introducing a dependency between services means that the high uptime and reliability which makes microservices attractive in the first place takes a bit of a hit.
For example, Service A has to call Service B and then also call Service C to complete a request. If at any point in this chain there’s an issue with Service B/C the entire request fails or if Service B/C is slow the entire request is slow. I’ve tried to illustrate this in the diagram below:
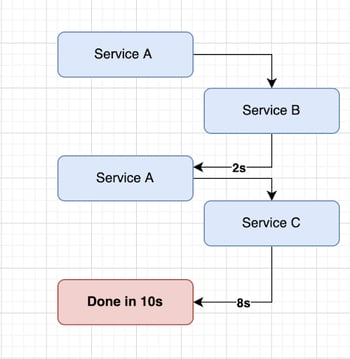
As mentioned above, in a bigger app, we may have many services that end up calling many other services internally. As a result, and when this nesting becomes multiple layers deep, any other service we call could now be calling many other services itself, as I’ve tried to illustrate in the diagram below with Service B:
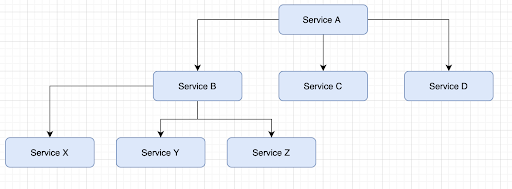
You can see how this would quickly spiral out of control as we add more services and dependencies. How many services do Services X,Y and Z call internally? How long would the request to Service A take? Do any of these other services we’re calling also call Service A themselves? The end result is something very slow and fragile and unless you have some excellent logging, very tricky to debug - which sounds just like a monolith.
Asynchronous communication between services
The alternative to this is implementing an asynchronous style of communication, where our services communicate with each other using an event-based system and Eventbus such as RabbitMQ, Kafka, or NATS.
Event-based communication would solve our problem of nested dependencies by having our Eventbus listen for events from all our services as well as emit events back to them. Each individual service can then subscribe to any events it cares about that are emitted by the Eventbus and process the data they contain, however it needs to.
The Eventbus would not mutate or perform any additional logic on the data that passes through it and instead, as the name suggests, forwards data to the services that care about it. The Eventbus also has no knowledge of the internal workings of any particular service. It receives an event with some data and emits an event with the same data.
In the case of the example above where Service A is calling Service B and then calls Service C, we would instead have Service A emit an event which Service B and C can listen for and then emit their own events, which contain any data needed in order for the request to be successfully completed.
Here's a simplified diagram that shows what event-based communication might look like. I’ve given the services some generic names so it makes a bit more sense:
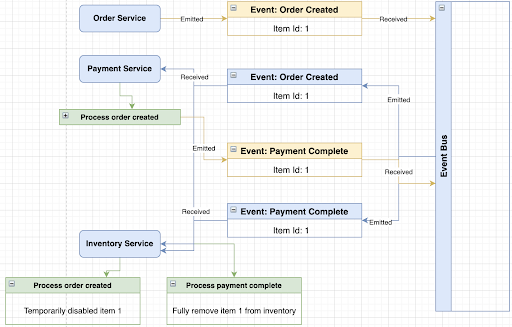
The diagram above is a very contrived example but hopefully it gets the point across. Our Order service is emitting an event to the Eventbus and the Eventbus has multiple services listening to the “Order created” event and doing something different with it internally. This approach is much faster in terms of performance and a lot more scalable, if we overlook the initial complexity of its setup.
Downtime and syncing events
Now, what should we do if a service is down for a longer period of time or if we’ve just created a new service entirely that needs access to previous events that were emitted while it was down or before it existed? The solution for that is actually fairly simple, we just keep a record of all events ever emitted and their data in a database. This way, a service can query this database for events in the timeframe it was down or just query the database for all events and catch up to the present day by processing all relevant events as if it has always existed.
Code reuse or sharing between services
Just because the services are self-contained doesn’t mean we now need to have duplicate code. As expected, some of the code in our services would need to be very similar, error handling and utilities for example could be reused. Here at goodlord.co we would most likely go with the approach of hosting an NPM package with everything we can reuse and import it directly into each service where needed. This is a fairly straightforward process but will require you to pay for the private organisation package.
That’s all for this overview, I recommend further reading on everything mentioned if it’s a topic you find interesting, as all of the points are oversimplified examples. Thanks for reading!
Want to advance in your tech career? Check out the jobs we have available.